


编辑:定慧
【导读】ChatGPT捅破大学作弊天花板,美国高校陷前所未有信任危机:从被哥大开除的「AI作弊明星」Roy Lee,到教授们徒劳识别AI论文,一代学生在ChatGPT陪伴下成长为「文凭文盲」。当大学的知识、学历与能力脱钩,谁来为崩塌的教育买单?
「美国的高等教育就是个笑话!」
还记得Roy Lee小哥吗,因为公开自己全程使用AI「作弊」通过了亚马逊的笔试,而被哥伦比亚大学开除。

Roy Lee最开始出圈的产品,帮助程序员作弊算法问题
当然,小哥并没有气馁,立马转身创业开办了Cluely公司,专门教人「在所有事情上作弊」,还收到了530万美元的天使投资。
这一次Roy Lee准备加倍押注这个趋势:不仅是找工作,美国大学也要「完蛋」了!

在通过AI作弊获取Offer后,大家开始通过ChatGPT「作弊」混过大学。
「大学的唯一作用只剩下找到自己的合伙人和妻子」,Lee表示,只有离开大学,你的生活才算真正开始。
在最新的一次采访中,James Walsh借用Lee的故事开头,讲述了当下美国大学正在如何被ChatGPT「攻破」。

不论是美国的大学生还是高中生,没有人可以拒绝ChatGPT。
-
「有了ChatGPT,我可以2小时完成一篇过去需要12小时的论文」
-
「谁又能抵挡住这种看似毫无后果,让每项作业都变得更简单的工具呢?」
-
「我在课堂上看到几乎所有其他学生的笔记本电脑都开着ChatGPT」
新生们和老生们都表示自己已经对ChatGPT上瘾,就像对TikTok、Instagram和Snapchat上瘾一样,但是老师们却感觉很绝望。
大学毕业的「文盲们」
Troy Jollimore,是一位诗人、哲学家,也是加州州立大学奇科分校的伦理学教授。
在过去两年的大部分时间里,他一直在批改由AI生成的论文,这让他感觉很痛苦,很担忧。
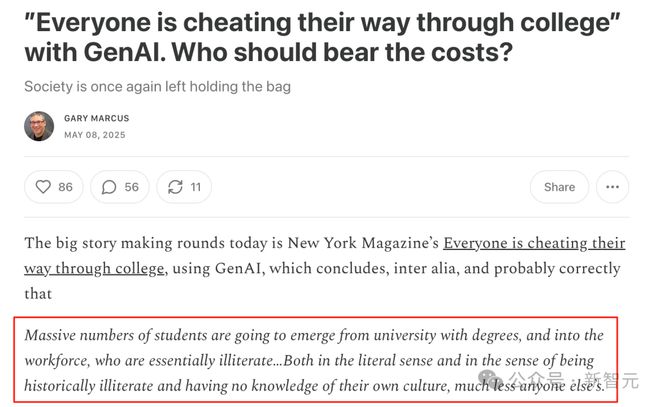
大量的学生将从大学毕业,带着学位进入职场,但实际上他们几乎是文盲。
无论从字面意义上来说,还是从对历史一无所知、对自己文化不了解,更别说了解其他文化的角度来看,都是如此。
考虑到大学教育在人生中实际上是一个很短的时间窗口,一大批「文盲们」从大学毕业进入社会这个事实也许比预期来的更快。
另一个数据也能说明问题,已经有大约一半的本科生,从未经历过没有生成式AI的大学生活。
就像我们常说的「数字原住民」,一出生就被各种Led屏幕环绕;而未来的学生们,从高中开始就被「ChatGPT们」包围。
这代表了一整代人的「学习过程」可能遭受了严重破坏。
老师们为了防止学生用AI作弊,尝试了各种应对方法,比如重新使用蓝皮书答题册,或者改用口头考试。
Santa Clara大学的科技伦理学者Brian Patrick Green在第一次尝试ChatGPT后,就立刻停止了布置论文作业。
不到三个月后,他在教授一门名为《伦理与人工智能》的课程时,认为一次简单读书反思写作应该不会导致学生们滥用AI——他觉得没人会用ChatGPT来写一篇个人化的感想。
但其中一位学生交上来的反思却用词僵硬、语气机械,Green一看就知道是AI写的。
没有什么能够阻挡ChatGPT的「入侵」了。
作弊又不是什么新鲜事儿,正如一位学生所说,「天花板已经被打破了」。
被ChatGPT捅破的「天花板」
其实学术作弊一直就有,在OpenAI于2022年11月发布ChatGPT之前,还有很多工具扮演类似的角色。
当时,许多大学生是在远程上完课程的——意味着几乎没有监督——而且可以轻松使用Chegg和Course Hero等工具。
这些产品对外宣称都是什么「在线教科书」或者「课程资料库」,但实际上都是「作弊神器」。
只需每月支付15.95美元,Chegg就承诺可在30分钟内、全天候提供作业答案,这些答案来自其聘请的15万名拥有高等学历的专家——大多是在印度专家。
在ChatGPT出现前,这个「作弊天花板」确实不是很高,毕竟还需要人类全天候待命,人力成本也不低。
但ChatGPT的出现,捅破了这层天花板。
和过去的「人」的方式比起来,AI更快、更强、更智能、更能迎合学生的口味。
但面对这一局面,学校和管理者们无从下手。
全面禁止ChatGPT几乎不可能。
于是多数高校只能采取临时对策,将这个问题的负担抛给教授们。
让教授自行决定是否允许学生使用AI。
一些大学甚至持欢迎态度,与开发商合作,推出自己的聊天机器人来协助学生选课,或开设生成式AI相关的新课程、证书项目和专业。
但规范使用AI的难度依然很大:AI协助的「底线」应该在哪?学生是否可以与AI对话获取写作思路,但不能直接让它撰写内容?
在教授老师们各自苦恼时,学生们也挺苦恼——ChatGPT的能力太强了,远超学生们的实力。
Wendy每次写作文时(每次写作文都会用AI),第一步都会执行一个步骤。
「我会说我是大学一年级学生,在上英语课」。
Wendy解释说,如果不这样进行系统级别的设定,AI会给出非常高阶复杂的写作风格,而那不是她想要的,也不是现阶段她的水平能写出来——老师们一眼就能出到底是「谁」写的。
无法被鉴别的「作品」
学生怕ChatGPT水平太高,无法有效地模仿他们。
但是,老师们又面临另一个问题,ChatGPT水平太高,有时候AI写的东西,他们无法「鉴别」出来。
很多大学的教授们很自信:我能够一眼看出谁的作业是AI写的。
但研究发现事实并非如此。
2024年6月发布的一项研究设立在英国一所大学内,研究人员用虚假的学生身份提交了完全由AI生成的作业,结果教授们未能识别出97%的AI写作。
ChatGPT不仅捅穿了作弊的天花板,而且写作风格和人越来越像。
因此,很多大学开始使用AI检测工具,如Turnitin,这类工具利用AI识别文本中可能存在的AI生成模式。
有学生表示,一些教授被传言设有某种阈值(比如25%),超过这个数值的作业就可能被视为「作弊」。
但是大多数教授已经默认这些AI检测工具并不可靠——人都看不出来,更不想承认人还不如检测工具。
当然,学生们也不都是笨蛋+「文盲」。
有很多简单的方法可以欺骗教授和检测器,在使用AI生成论文后,学生可以用自己的语气重写它或添加拼写错误——换个更容易理解的词语就是洗稿。
或者不用这么「麻烦」,有的学生直接对ChatGPT说「写得像一个有点傻的大一新生」。
所以你看,还是AI好用,这个要求要是提给人类,或多或少会觉得不舒服,但AI不会。
AI没有情绪,不会疲惫,不会质疑你,也不会对「作弊」这件事露出鄙夷的眼神。
对它来说,一切只是指令和响应。
而有时候,一个人之所以依赖AI到如此地步,不是因为他懒,而是因为——他已经对「美国高校」彻底失望了。
一个被「伤透心」的孩子
让我们回到Roy Lee身上。
你会不会好奇,Lee小哥为何对大学教育有这么大的「怨念」?
其实在被哥伦比亚大学开除以前,Roy Lee甚至还「上过」哈佛大学——其实是被提前录取,但是由于高中阶段「作死」而被哈佛大学取消了资格,由此可见Lee的性格!
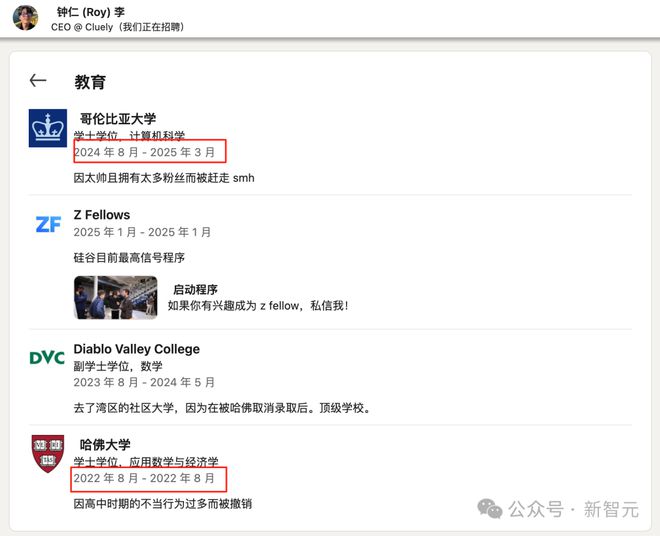
Lee出生在韩国,在亚特兰大长大,他的父母在经营一家大学预备咨询公司。
他说他在高中最后一年的早期被哈佛录取,但在毕业前的一次过夜实地考察中偷偷溜出去后被学校停学,哈佛撤回了录取通知。
一年后,他申请了26所学校,但没有一所录取他!
因此,他在社区学院度过了一年,之后转到了哥伦比亚大学。
关于这段曲折的经历,Lee小哥让ChatGPT帮他润色了一下:「将他(Roy Lee)曲折的高等教育之路变成了他建立公司的雄心的寓言」。
当他在去年九月作为二年级学生开始在哥伦比亚大学的学习时,他对学术或绩点并不太担心。
「大多数大学作业都可以通过人工智能来完成,而我对此毫无兴趣。」
当其他新生为学校的严格核心课程焦虑时,Lee利用人工智能以「最小的努力」轻松通过。
而剩下的时间,促成了他后来的「壮举」:记录了整个面试亚马逊的流程——从OA到最终offer。
「我发布了视频。它开始火了起来」。

当然结果并没好,哥伦比亚大学开除了他。

后来的故事,我们都知道了,Lee退学后筹集到530万美元开始创业,而目的只有一个「在所有事情上作弊」。
但当作弊成为「默认选项」——不论是伤心的Lee小哥,还是无法拒绝ChatGPT的大学学生们——真正值得追问的不是「谁作弊了」,而是「谁应该为这一切买单」。
这个成本,不只是成绩失真或学术堕落那么简单,更是整个美国高等教育系统在价值定位、激励机制和学生心理健康之间失衡所造成的溢出代价。
谁应该承担这个成本
记录Lee的故事以及讲述ChatGPT如何被学生们用来作弊的文章《大家都在作弊混过大学》目前讨论的热度非常高。
互联网上最有名的「喷子」之一Gary Marcus认为,「大量的学生将从大学毕业,带着学位进入职场,但实际上他们几乎是文盲」可能是这篇文章最正确的结论。
所以,使用ChatGPT作弊这件事要怪罪在学生头上吗?
但是另一篇帖子提出了不一样的看法,「有人停下来问过为什么学生会作弊吗?」
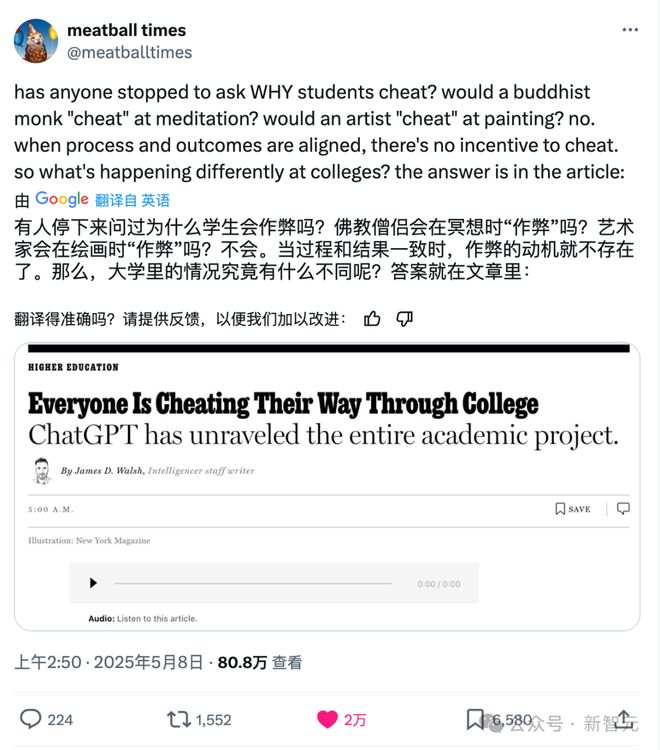
佛教僧侣在冥想时会作弊吗?艺术家在绘画时会作弊吗?如果真的热爱一件事,比如学习,还会为了「逃避」考试而作弊吗?
这是一个非常触及灵魂的提问。
metaball认为这篇文章的作者「错误地认为」常春藤盟校是关于教育的。
而Lee是明白人,常春藤盟校是关于精英培养和人脉建立的。
对于常春藤盟校来说,「所有」学业都是干扰。
扎克伯格从哈佛学到了很多——但从来不是在课堂上。他得到了他需要的东西,然后退学了。
曾经作为退学后创业成功的「明星们」似乎也在证明这个事实——学业对未来的工作似乎帮助并没有太大。
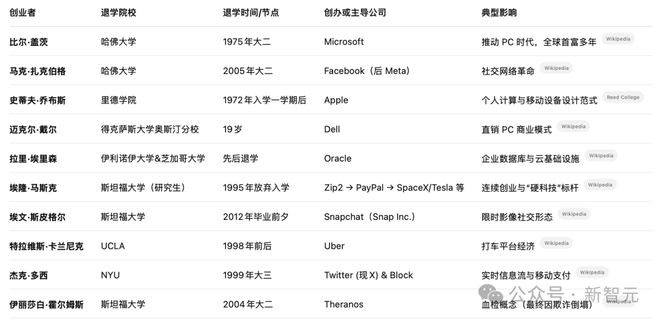
些许讽刺的是,这份总结也是ChatGPT整理的
作弊是通过学校拿到你需要的企业工作文凭的最经济有效的方式。
在这个讨论中,meatball提出了当下美国大学教育为何会被ChatGPT「攻破」的几个理由:
-
大学通识教育的目标和以就业导向的目标是根本上不兼容的
-
评估学生的方式有糟糕的激励机制,而且无论如何也没有预测性
-
在大学里进行的学习与现实世界的目标关系非常弱
针对这些问题,看似只要修修补补——优化教学设计、提升课程实用性、引入AI工具,学生就不再有作弊的冲动。
但是大学教育终将不得不重新思考一个根本问题:究竟为何而学?
也许下一个需要被刷新重构的,不只是教育制度,而是对「知识」「学历」「能力」三者关系的整个认知框架。
然而,当这一切真的做到后,所有人可能都会面对一个「可怕」的真相:
那个被修复后的大学,可能早就没有剩下多少「本体」了。
这,才是美国大学和教育工作们最深的恐慌吧。
参考资料:
https://nymag.com/intelligencer/article/openai-chatgpt-ai-cheating-education-college-students-school.html
https://garymarcus.substack.com/p/everyone-is-cheating-their-way-through
内容来源于网络。发布者:科技网btna,转转请注明出处:https://www.btna.cn/7997.html